Abstract
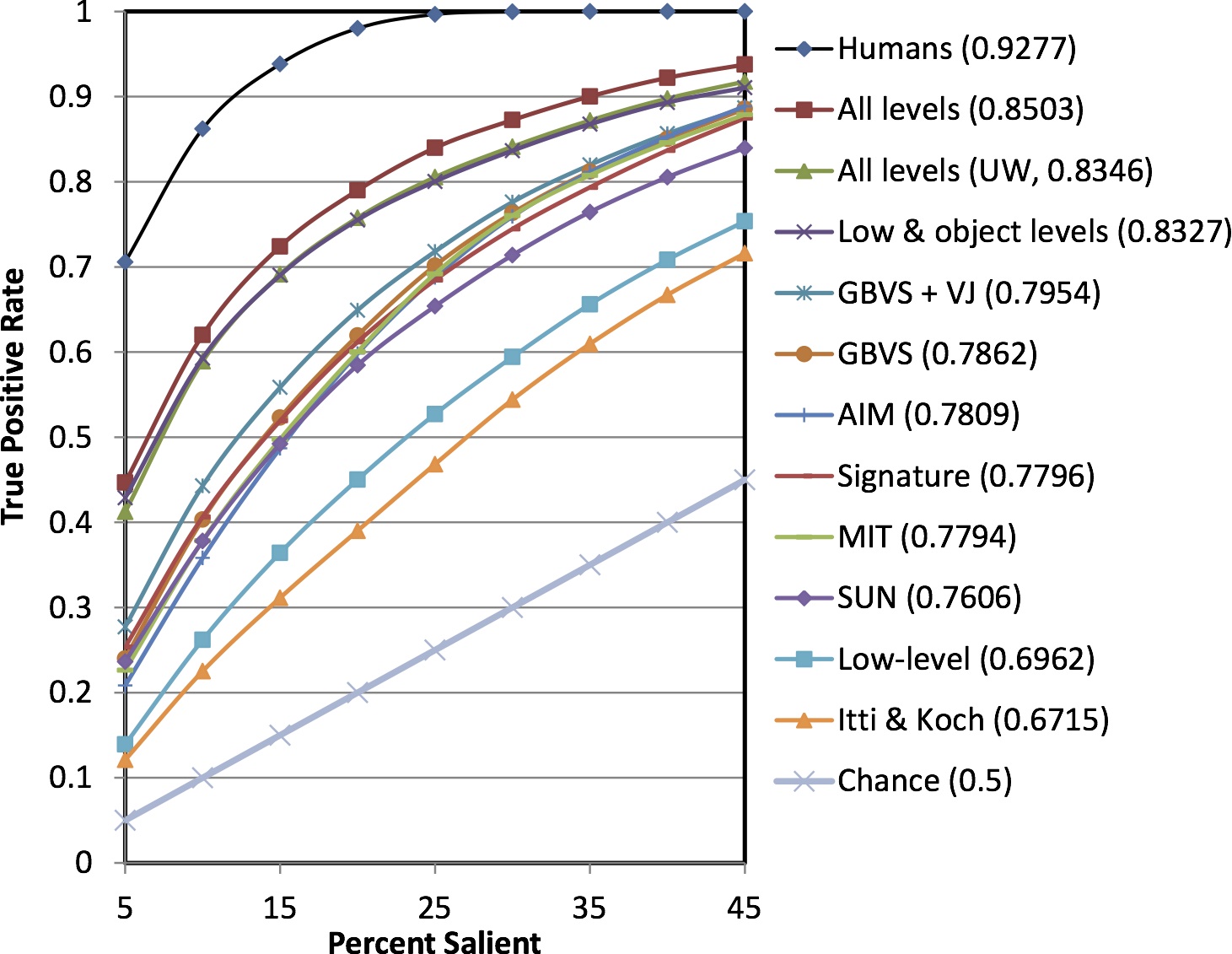
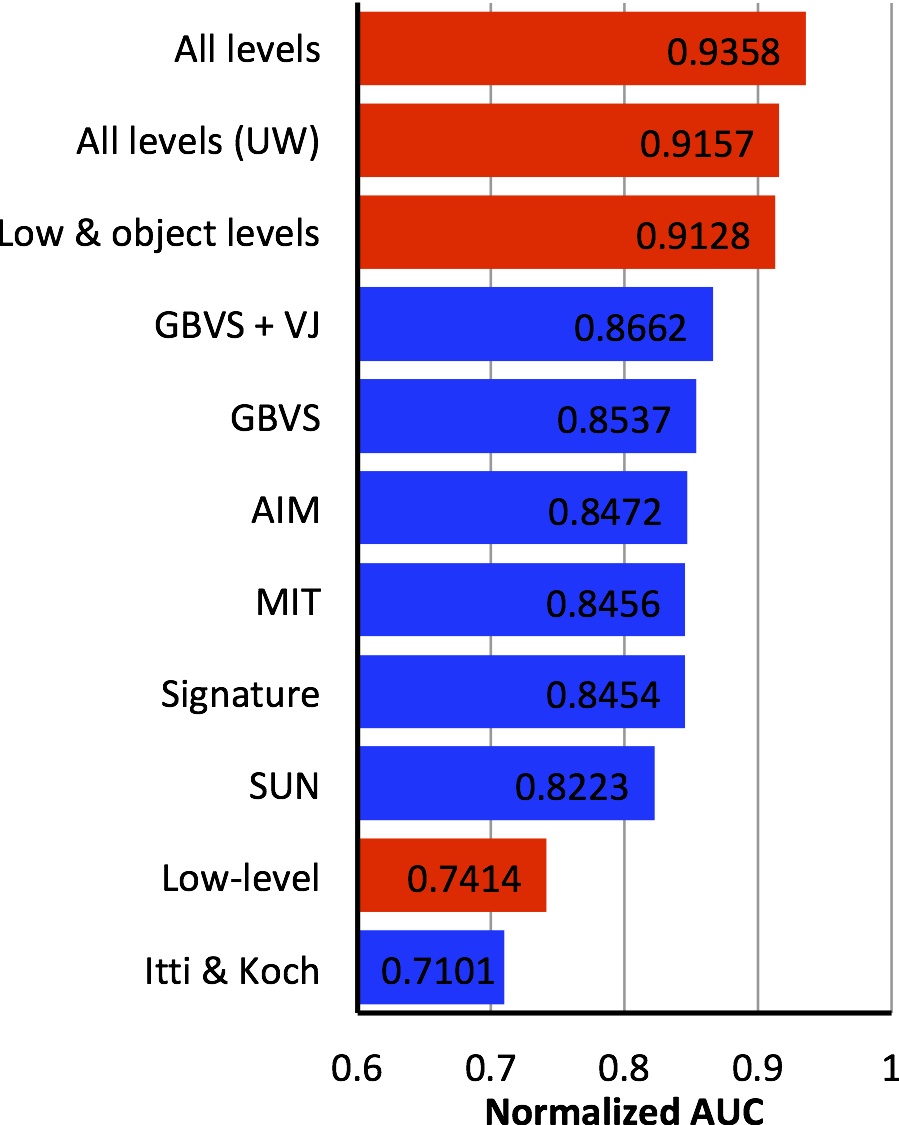
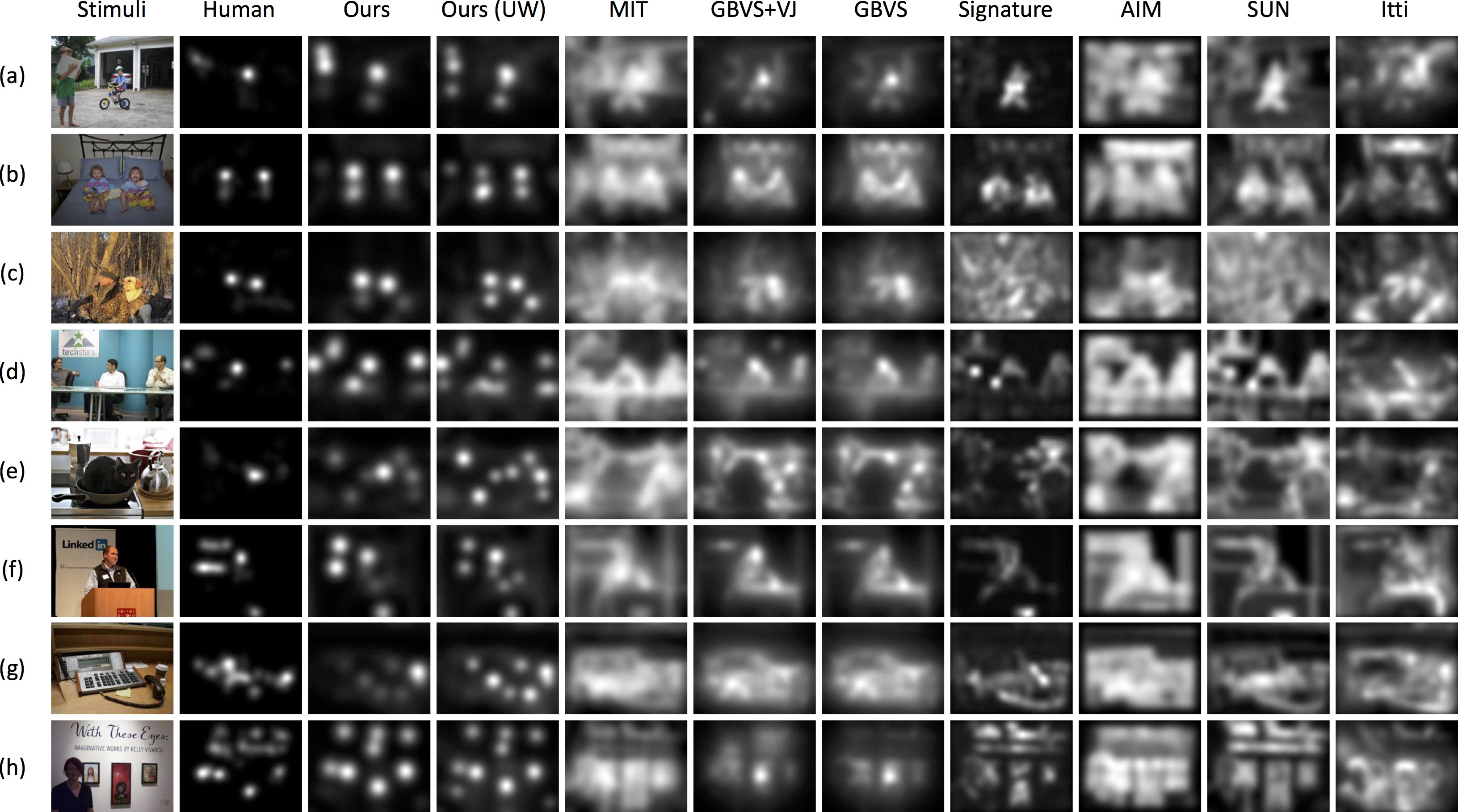
A large body of previous models to predict where people look in natural scenes focused on pixel-level image attributes. To bridge the semantic gap between the predictive power of computational saliency models and human behavior, we propose a new saliency architecture that incorporates information at three layers: pixel-level image attributes, object-level attributes, and semantic-level attributes. Object- and semantic-level information is frequently ignored, or only a few sample object categories are discussed where scaling to a large number of object categories is not feasible nor neurally plausible. To address this problem, this work constructs a principled vocabulary of basic attributes to describe object- and semantic-level information thus not restricting to a limited number of object categories. We build a new dataset of 700 images with eye-tracking data of 15 viewers and annotation data of 5551 segmented objects with fine contours and 12 semantic attributes. Experimental results demonstrate the importance of the object- and semantic-level information in the prediction of visual attention.
The stimuli feature in rich semantics and annotations in natural scenes, and have been used in a number of neuroscience works (autism eye-tracking, fMRI, single-unit, etc). Multi-modality data will be added. [more datasets]
Resources
Paper
Juan Xu, Ming Jiang, Shuo Wang, Mohan Kankanhalli, and Qi Zhao, "Predicting Human Gaze Beyond Pixels," in Journal of Vision, Volume 14, Issue 1, Article 28, Pages 1-20, January 2014. [pdf] [bib]
Image Stimuli 700 Images (47 MB)
Eye-tracking Data Matlab MAT (1 MB)
Mouse-tracking Data Experiments with Amazon Mechanical Turk: Matlab MAT (20 MB), controlled experiments in Lab: Matlab MAT (4 MB)
Labelled Object Contours and Semantic Attributes Matlab MAT (45 MB)
Codes GitHub Codes for "Predicting Human Gaze Beyond Pixels," JOV 2014. It contains object and semantic feature computation, model training with SVM, saliency prediction, and evaluation measures.
Attributes

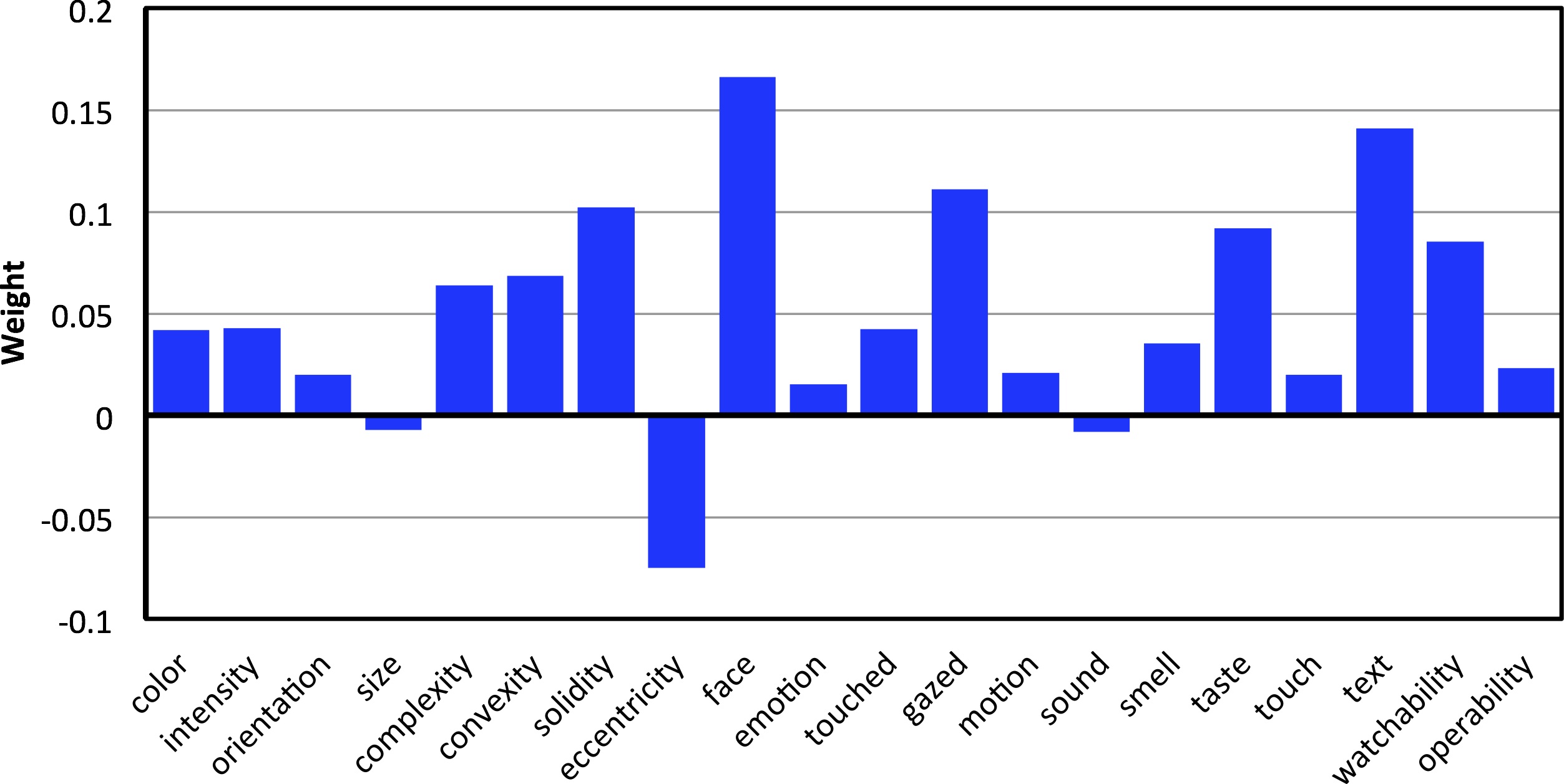

Results