Decentralized Distributed Deep Learning (DL) in TensorFlow
Overview
This is a TensorFlow implementation of Ako (Ako: Decentralised Deep Learning with Partial Gradient Exchange). You can train any DNNs in a decentralized manner without parameter servers. Workers exchange partitioned gradients directly with each other without help of parameter servers and update their own local weights. Please refer Ako paper for more details.
Distributed Deep Learning
Multiple machines can be used to train a deep learning (DL) model given a large size of data. There are three kinds of parallelisms – Data, Model, and Hybrid parallelism. For data parallelism, the input data is partitioned and distributed to multiple machines which each machine has an identical whole DL model. For model parallelism, the model is partitioned and distributed to multiple machines while each machine processes the same whole data. For hybrid parallelism, both the model and data are partitioned and distributed to machines. Since the size of data is relatively much larger than the one of DL models, and it is the main cause of the lack of storage resource, the data parallelism is most frequently used in current deep learning.
There are two different ways to update weights of DL models in training phase – Centralized and Decentralized deep learning. Figure 1 illustrates the centralized DL and figure 2 demonstrates the decentralized DL.
Centralized Distributed Deep Learning
In the centralized DL, there are central components called parameter servers (PS) to store and update weights. The number of parameter servers can be one to many, which depends on the size of weights of a DL model or policies of the application. Each worker pulls the latest values of the weights from the parameter servers, calculating gradients with the weight values and their data, and then pushing the gradients to the parameter servers. The parameter servers update the weights by applying the gradients collected from all the workers through back propagation.
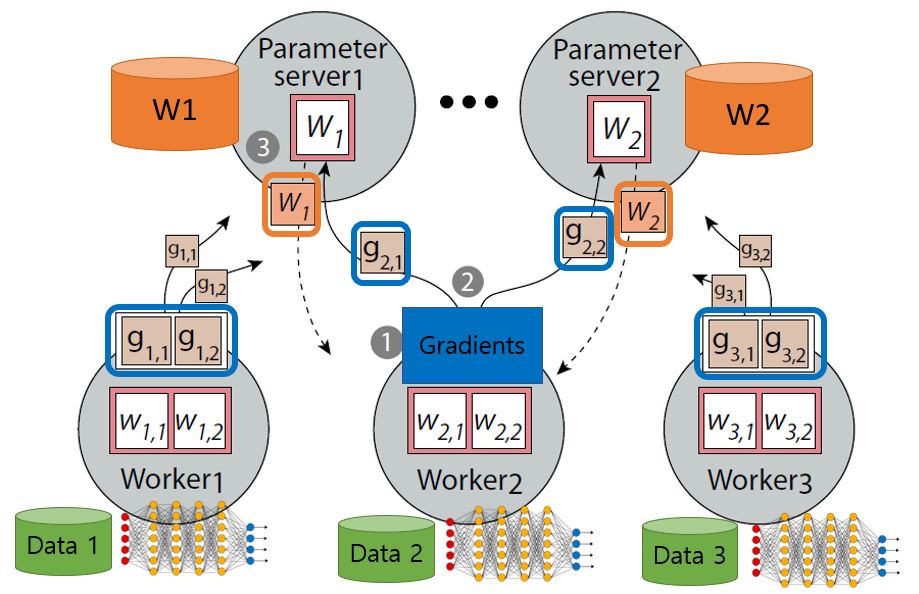
< Figure 1. Centralized Distributed Deep Learning >
Decentralized Distributed Deep Learning
In the decentralized DL, there are no central components, parameter servers. Every worker maintains the latest values of the weights by themselves. They do not exchange any weight values from others, yet they update their own weights through gradients of others. The final weights of the workers can differ from each other as training goes since they do not synchronize the weights in any phases in the decentralized DL. Therefore, their accuracies are more susceptible to different initial values of weights and different training speed of individual workers than the ones in the centralized DL. In the other hand, workers sharing parameter servers can have relatively similar weights at the end since they start gradient calculation every step with the same weight values.
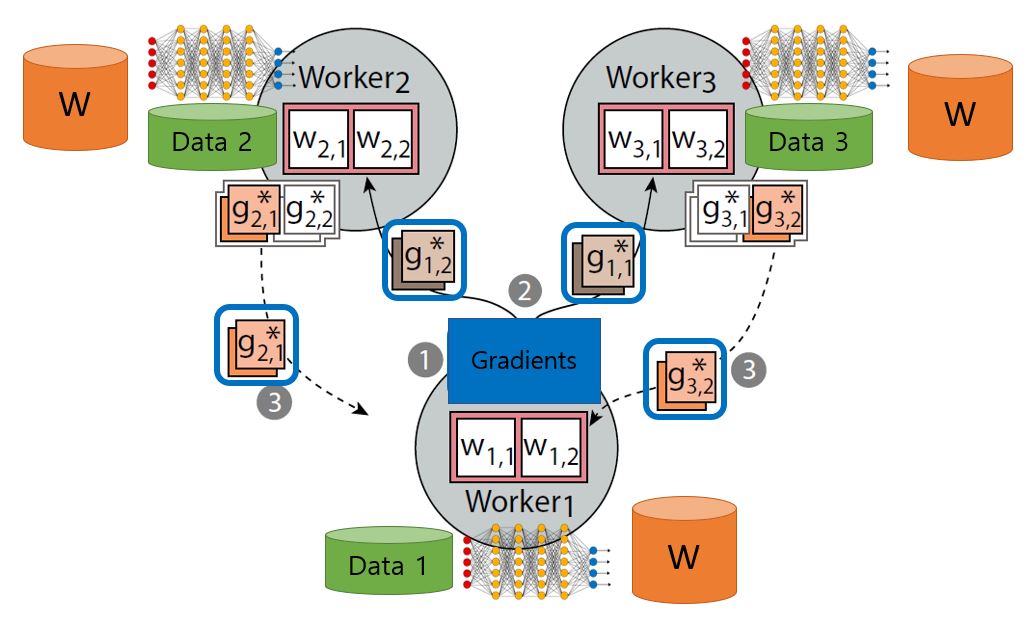
< Figure 2. Decentralized Distributed Deep Learning >
Setup
Installation
You can access the source code from github.
Environments
- ubuntu 16.04
- Python 2.7
- Tensorflow 1.4
Prerequisites
- redis-server & redis-client
- tflearn (only for loading CIFAR10 dataset)
$ sudo apt-get update $ sudo apt-get install redis-server -y $ sudo pip install redis $ sudo pip install tflearn
How to run
- Build your model in redis_ako_model.py
- Write your session and load your dataset in redis_ako.py
- Change your configurations in redis_ako_config.py
- Basic configurations: Cluster IP/Port, Redis port, Synchronous training, Training epochs, Batch size, Number of batches
- Ways to train models: training a few iterations, training for a fixed time, training until a fixed accuracy
- Ako specific configurations: P values, partition details, SSP interation bound, Number of queue threads
- Execute it
# When 3 workers are clustered and used for decentralized DL # At worker 0 $ python redis_ako.py wk 0 # At worker 1 $ python redis_ako.py wk 1 # At worker 2 $ python redis_ako.py wk 2
References
- Rankyung Hong's Plan B final report: Exploring Decentralized Distributed Deep Learning in LAN and WAN environments (here)
- Watcharapichat, Pijika, et al. "Ako: Decentralised deep learning with partial gradient exchange." Proceedings of the Seventh ACM Symposium on Cloud Computing. ACM, 2016.
- Abadi, Martín, et al. "Tensorflow: Large-scale machine learning on heterogeneous distributed systems." arXiv preprint arXiv:1603.04467 (2016).
- Abadi, Martín, et al. "TensorFlow: A System for Large-Scale Machine Learning." OSDI. Vol. 16. 2016.
- Hsieh, Kevin, et al. "Gaia: Geo-Distributed Machine Learning Approaching LAN Speeds." NSDI. 2017.
- Krizhevsky, Alex, and Geoffrey Hinton. "Learning multiple layers of features from tiny images." (2009).
- https://www.tensorflow.org